Introduction to Proximal Policy Optimization (PPO)


The previous blog post looked at the Vanilla Policy Gradient (VPG) method.
Trust Region Policy Optimization and Proximal Policy Optimization build on top of VPG and aim to address its shortcomings.
stablebaselines3. You can find the code I wrote while working on this blog post here.PPO addresses two main problems with training on-policy reinforcement learning algorithms:
- Training data distribution shifts
In on-policy methods, the training data is generated by the policy under training as it interacts with the environment.
As we train our policy, its behavior changes — and so does the distribution of our training data.
This can cause trouble, since the hyperparameters that worked in an earlier stage of training might no longer work well.
- Inability to recover from poor updates
If our policy is updated during training in a way that produces very poor actions, we might not be able to recover from that state.
A policy pushed into a region of the parameter space that doesn't function well will produce low-quality data in the next sampled batch!
This can create a self-reinforcing loop that the policy never escapes.
The solution
Trust Region Policy Optimization (TRPO), and later Proximal Policy Optimization (PPO), solve both of these problems.
They can be reliably trained in high-dimensional and continuous action spaces, and they are significantly less sensitive to starting conditions and the choice of hyperparameters.
They do have one shortcoming: they are prone to converging to a local optimum. Still, overall they offer a significantly better training experience than VPG-based methods.
PPO is the successor to TRPO, so it's the one we'll focus on in this blog post!
Another nice advantage: in improving on TRPO, PPO also simplified the math and the implementation details — and that's not a property to overlook when you're working on a machine learning problem!
So, how does PPO work?
The core idea
At the heart of the method lies the cost function.

It looks complicated at first sight, but unpacked it reveals a simple yet ingenious idea!
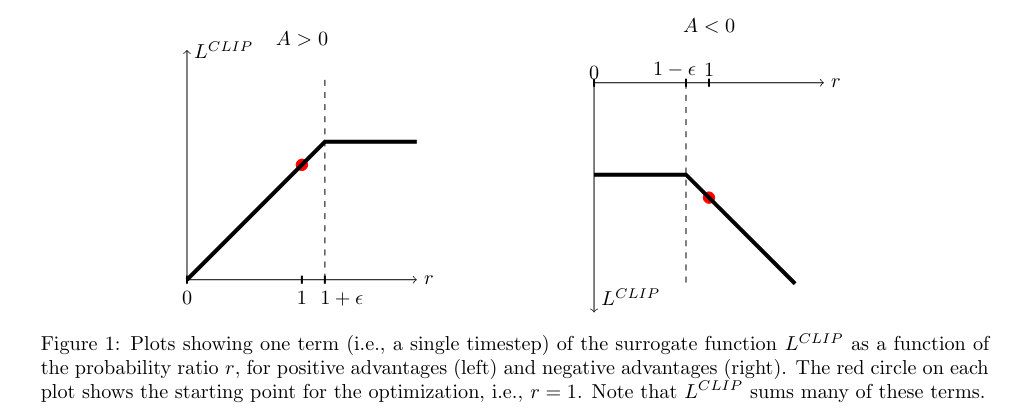
Let's start with the ratio of \(\pi_{\theta}(a|s)\) to \(\pi_{\theta_k}(a|s)\).
Here, \(k\) denotes the weights before the update (the ones used to collect the trajectories). The policy in the numerator is parametrized by the new \(\theta\) — the weights after an update — while the policy in the denominator uses the weights from before the current update.
This ratio captures the philosophy of PPO.
We compare the updated policy to the previous one. Where the ratio would be too high — meaning we've deviated further from the old policy than we'd like in the positive direction — we take a step of at most \(\epsilon\) in magnitude.
This safeguards us from making a large step through the parameter space, away from our current policy. As discussed earlier, doing so would risk overshooting the area of quick improvement and could carry us into regions where the policy becomes degenerate.
And since we use the policy to sample training data, we might not be able to recover from such a predicament!
Instead, we choose to take a smaller step, in the hope that our policy keeps improving monotonically.
On the other hand, if we're fixing an issue where the ratio is smaller than 1 (the policy before the update assigns a higher probability to a beneficial action than the policy after the update), the step is unbounded.
In the negative direction, we're happy to move as far as the calculation indicates:
Summary
Proximal Policy Optimization has been a significant advance in applying deep reinforcement learning to real-world problems.
OpenAI used PPO to train OpenAI Five, a system trained at an unprecedented scale that went on to defeat the reigning Dota 2 world champions — a striking demonstration of PPO on a complex strategic challenge.
It has also been adopted widely in robotics, where it's been instrumental in finding effective control policies. Its ability to handle continuous action spaces, together with its stability during training, has made it a popular choice there.
Here is a quick recap of the method I generated with Claude Opus:
The key idea behind PPO is that it uses a single policy and performs multiple epochs of updates on the same batch of collected trajectories. The probability ratio is calculated between the current policy (being updated) and the policy used to collect the trajectories (before the update). This allows PPO to make conservative updates to the policy while still improving its performance.
By using a clipping function in the surrogate objective, PPO prevents the policy from changing too drastically in a single update, which helps to maintain stability during training. The clipping function limits the size of the policy update by constraining the probability ratio within a certain range.
Very excited to be including PPO in my toolbox!