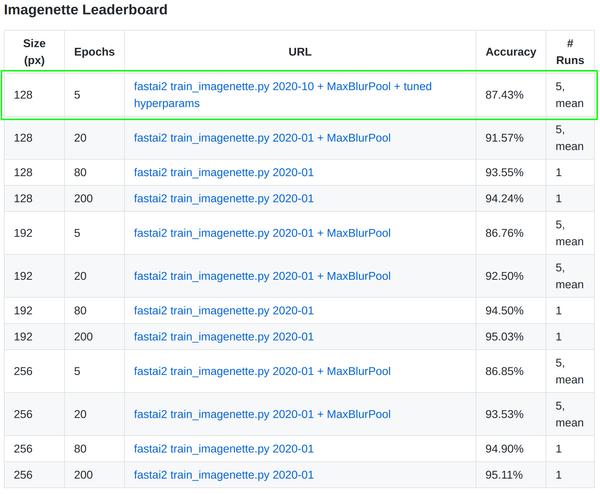
There used to be a time when fine-tuning LLMs on off-the-shelf hardware wasn't a thing.
Then the Llama weights got leaked, Stanford Alpaca was released, and the rest is history.
So how was Alpaca fine-tuned? And why might we care?
On one hand, Alpaca is where the Cambrian