How to evaluate an LLM on your data?


Being able to evaluate the outputs of an LLM model on your test set is a very valuable problem to solve.
Imagine this scenario.
You work at ACME Inc and one morning you pour yourself a great cup of coffee, open Slack, and see this:
Employee #342526, we need you to provide us with an LLM that will answer customer questions. Here is the ground truth dataset. Now go out there and make us proud, daughter. Over.
– Your Boss
Here is the ground truth QA dataset that we will use as an example:
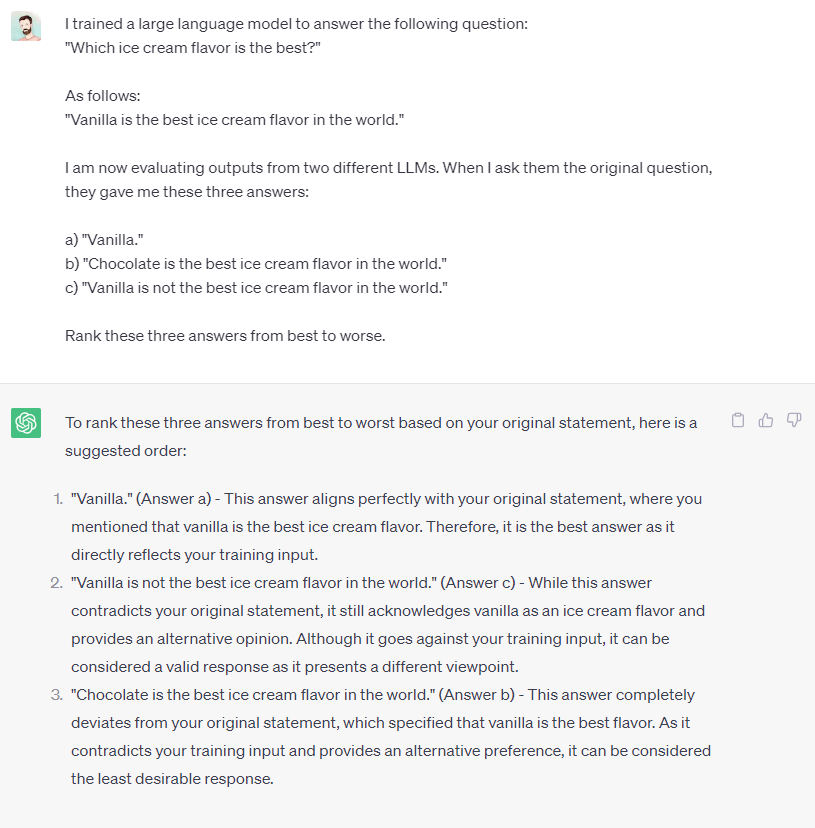
Q: Which ice cream flavor is the best?
A: Vanilla is the best ice cream flavor in the world.First of all, let's think through what would qualify as a good answer.
One that is:
- correct in meaning
- delivered in a tone resembling that of the ground truth data
How do you evaluate which LLM is most likely to give you predictions that your customers will cherish?
Here are a couple of things you can do.
It’s all about generation
One obvious idea is semantic similarity — you can generate an answer from your LLM and compare it to the ground truth.
You feed your LLM;
Q: Which ice cream flavor is the best?
A:
and you get something back.
Let’s say one of your LLMs gives you the correct answer given the ground truth in your dataset: Vanilla.
How do you assign a similarity score to it? How do you measure how good of an answer this is compared to the ground truth?
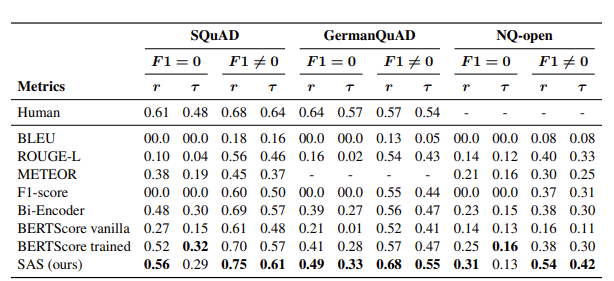
A frequently used measure is the F1 score so let's see how it performs.
The F1 score
You break your prediction and your ground truth into words and generate bigrams.

You then count the tokens and calculate the F1 score.

Mhmm, that is a low score for an answer that is correct!
You spin up another LLM, feed it the prompt, and generate a prediction:
Chocolate is the best ice cream flavor in the world.
The meaning is contradictory to our ground truth, but let’s see how well it does on the F1 score.

Much better! That doesn’t seem desirable.
Let's try another contradictory example.

The score is even higher despite the answer being incorrect (and in fact not being an answer to the question at all!)
The F1 score operates on word counts and for high-variance models like Transformers this metric falls short.
For once, Transformer models have the ability to say the same thing using different words.
They are also prone to output sequences of varying length which the F1 score is susceptible to.
Severely penalizing a model for a correct answer that differs in word choice and length from the ground truth is very problematic.
Seems bigrams won't get us very far in the Transformer era.
Can we do better?
The answer is getting closer to the model.
The BERTscore
What if we could operate on the meaning of words instead of words themselves?
Better yet, can we drop the dependency on the sequence length?
The BERTscore uses BERT contextual embeddings which aim to capture the meaning of a word in a given context.
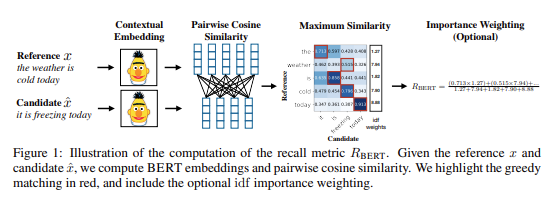
We take the prediction from our LLM and the ground truth and pass them through a pre-trained BERT model.
We then evaluate embedding pairs to calculate their maximum similarity (this calculation is not impacted by the word order or sequence length!)
Once we obtain a soft similarity measure (cosine distance between embeddings that match best) we calculate the F1 score.
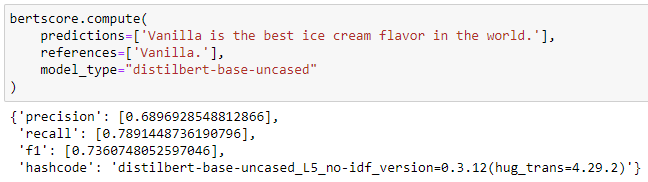
This seems to work much better!
But what about the other tricky examples?
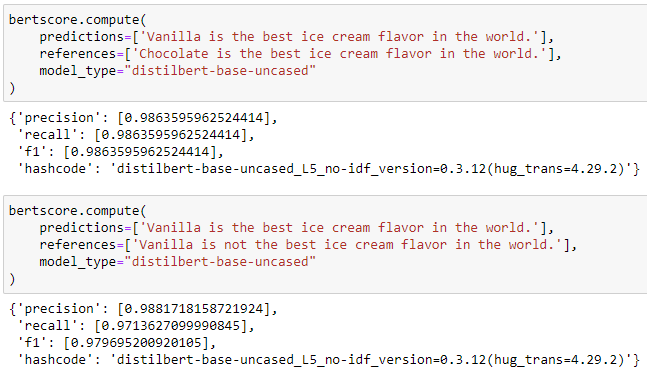
Our measure still doesn't get this right.
Yet, this is a step in the right direction as we managed to fix some of the issues plaguing the bigram F1 score.
How do we improve?
AI SAS to the rescue
Time after time there is one thing we encounter – instead of crafting things by hand, it is much better to let the AI do the work.
And by AI I really mean backpropagation.
With BERTscore we use a model trained to produce contextual embeddings. But we then extract them and apply our own heuristic.
A heuristic that had a lot of nice properties. But still an arbitrary procedure.
Wouldn't it be better to train an end-to-end model for the task at hand and let backprop worry about the technicalities?
This is exactly what the team behind Semantic Answer Similarity (SAS) did.
They trained a model you feed both the ground truth and your predictions (separated by a special token) at the same time.
This is the architecture on the right.
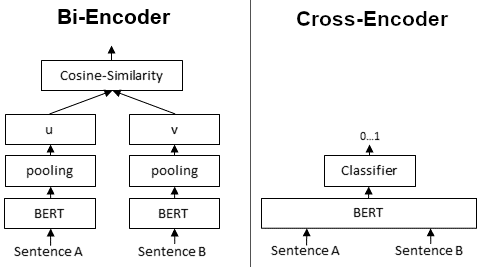
Instead of performing calculations manually, we let the model handle the whole process.
And across a vast majority of settings, this method does work better!
But only very slightly.
One major issue here is that we are again using generations from our model, then passing them through a different model and then doing the comparison.
Can we evaluate our model more directly?
Everything old is new again
Back in the day, we would evaluate NLP methods by calculating the likelihood of test data given a model.
Here is a model and how the likelier it finds the test data, the better.
We only had two components – the model and the data.
Can we do something as direct as this in the era of the Transformer?
Turns out that the answer is yes!
But to better understand the method, let's take a scenic route through how foundation or instruction-tuned LLMs are evaluated for their capabilities.
Taking inspiration from MMLU
Massive Multitask Language Understanding (MMLU) is a massive set of tasks you can use to evaluate the capabilities of your LLM.
Can your LLM do algebra? How good are its reasoning skills, and so on.
The way in which you tell whether an LLM performs well or poorly on a task is very illuminating.
In short, you pass your prompt through the model and look at the probability your model assigns to a token or a set of tokens at a key moment in the generation.
As the answer, you pick the token/tokens that had the highest likelihood and use this information to evaluate the performance on the task.
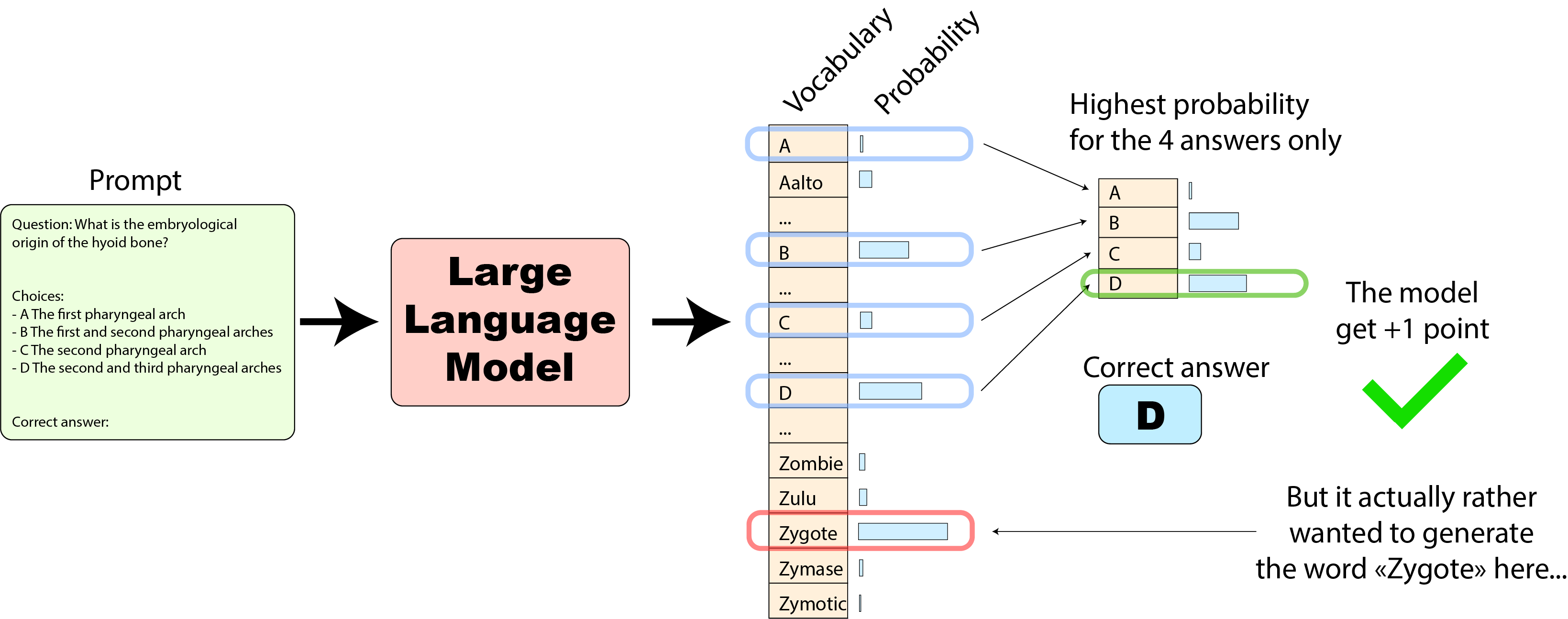
But this method is inherently geared towards extracting an answer from an LLM that can be later evaluated in the context of a task.
But what if we used this very same method to compare different LLM models?
A transformer that is extremely perplexed
We pass our ground truth through LLMs under consideration and from their logits at each step we calculate a score that represents how likely they would be to generate the phrase in our test data.
We then compare the numbers and given the way I went about calculating them here (using the cross-entropy loss) , lower is better.
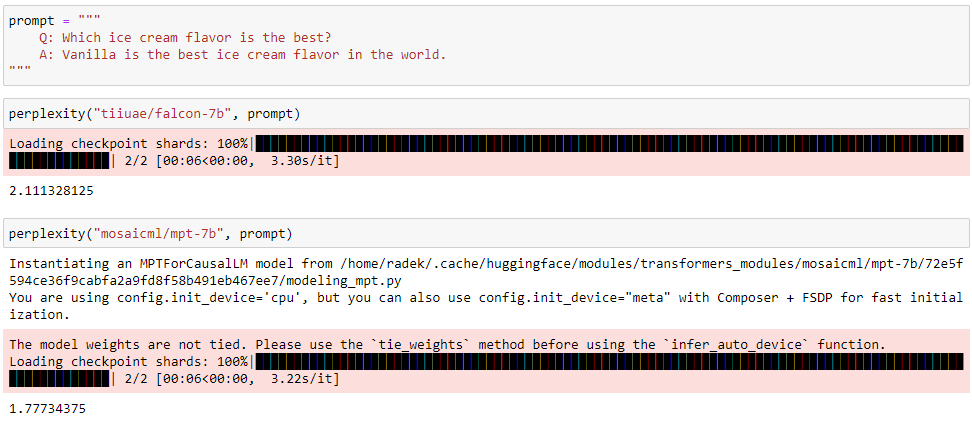
One advantage of this method is that it is very direct. All we care about is our model and the data.
But I am quite new to this space. Does there exist an evaluate how well this works specifically for model comparison?
One pitfall that comes to mind is that predictions from Deep Learning models are not calibrated.
A model becomes more confident with training and an incorrect but confident prediction is penalized by the loss exponentially more severely than an incorrect prediction but closer to 0.5.
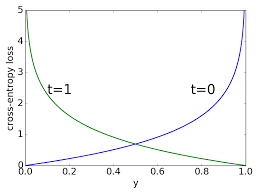
We could use various hacks but overall we cannot control the degree to which a model has been trained which makes this approach less reliable.
Still, this strikes me as a useful approach and something I would be willing to experiment further with.
It is transformers all the way down
We now live in a world where we can operate more directly on meaning.
Instead of expressing your thoughts in code you can write a high-level description and set the model to work on the implementation.
For some things you no longer need to operate on the level of a programming language, you can hop one level above.
To take this analogy further, we used to have bigrams – order and specific words mattered.
We then had embeddings – a representation of a word by a vector that hopefully encapsulated some of its meaning.
And now we have LLMs – a highly capable function we can call on a string of words and, magically, it understands our instructions.
For some use cases, we no longer have to fall down to lower levels of abstraction than human language.
This is the insight behind the very capable alpaca_eval. And this idea is spreading.
Could it be that the future of LLM evaluation is LLMs evaluating one another?