How to fine-tune a Transformer?


I only started to learn about LLMs and in this blog post, I share how I would approach fine-tuning a Transformer today.
Which of the techniques I learned years ago still work in the era of the Transformer?
Also, toward the end of the blog post, I address the training data generation capabilities of LLMs. This introduces a completely new and very exciting dynamic to the training of AI models!
In this blog post, we will fine-tune a Deberta V3 Large model for the Kaggle - LLM Science Exam competition that is currently underway.
Setting up the stage
The first order of business – we construct a MultipleChoice model based on the trained Deberta backbone.

This entails creating a new head with freshly initialized weights.
If we were to start training right now, gradients flowing through the untrained head would carry very little useful information.
Instead of adapting our model to the task at hand, the weight updates would compensate for what the untrained head was doing!
This could negatively affect the information accumulated in the pretrained weights and this is certainly not something that we want!
Thankfully, there is an easy fix.
We train just the head and keep the rest of the model frozen.
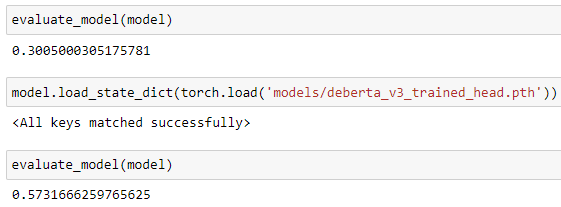
This doesn't lead to great performance, but it sets us up nicely for training the rest of the model!
Going back to the origin
What hyperparameters should we use for training?
We could start by making an educated guess. But there is a better way!
Let us instead find out how the model was originally trained and use this as a starting point.
Looking through the repository the creators of Deberta were very kind to make public, I discover that a comparable model was trained with a learning rate of 1e-4 and a batch size of 256.
Also, linear warmup was used quite extensively which seems to be the staple of training Transformer models!
I will be training on a 48GB GPU and with a model of this size, I will not be able to come even close to a batch size of 256.
However, it seems that 45 examples per batch should be doable.
I linearly scale the original learning rate (1e-4/256 * 45 = 1.75e-5) and perform a couple of short test runs with a comparable optimizer (AdamW) – the model seems to be training well!
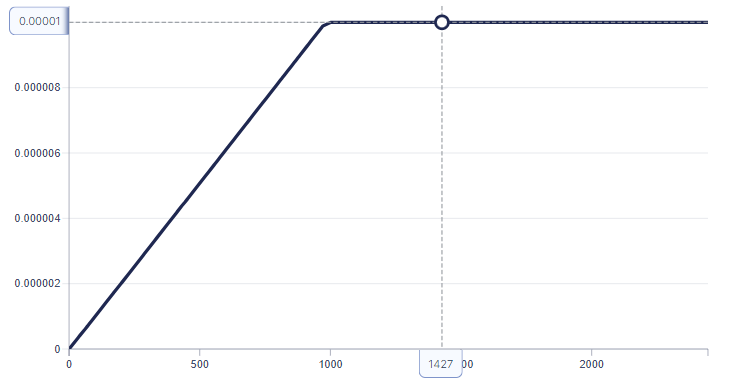
lr tracked by my favorite experiment-tracking software, aimAbove all – do no harm
The next couple of techniques I outline are inspired by the seminal paper, Universal Language Model Fine-tuning for Text Classification.
First of all, we probably don't want to fine-tune word embeddings.
I did my best to ensure the quality and diversity of the data I plan to train on.
But in no way is it comparable in diversity and size to the data the model was pretrained on!
It is unreasonable to assume the model will learn anything particularly useful about the meaning of words (on top of what it already knows) during the relatively short training on our data.
Taking this into consideration, and being mindful of the harm training on less diverse data can cause to the model, I attempt to train with the word embeddings frozen.
This reduces the number of trainable parameters from 435 million to 304 million.
First, I train the full model across 3 runs. When I take a mean ensemble of the predictions, the model achieves a map@3 of 0.739 (as measured on a 1k validation set).
With the embeddings frozen, the model achieves a map@3 of 0.742!
A small improvement but an improvement nonetheless!
Another trick up my sleeve
Just as we might not want to fine-tune the word embeddings, we probably do not want to train the bottom part of the Transformer as much as we train the upper one.
The reasoning is similar though it is pure speculation at this point.
Just as word embeddings encode the meaning of words, it is likely that the lower parts of a transformer encode the language model (rules of grammar, the meaning of punctuation, and so on).
Again, this is not necessarily something that would require changing for the model to perform well on the task we are adapting it to!
I perform another 3 training runs with the word embeddings frozen and with differential training rates.
I cosine-scale the learning rates so that the lower portions of the model receive less training.
With these changes, the ensemble achieves a map@3 of 0.748!
Discovering a new dimension
For this competition, I came up with a good way to generate additional train examples using gpt3.5-turbo.
Here is how this makes me feel:

Transformers are very high-variance and they will pick up on any regularity in your training data with ease. Thus training with diverse data is key!
But as I keep adding train examples... the results keep improving!
And not only can I generate more examples, but I can improve on how I generate them!
What are the things I can tune?
- Few-shot learning performs better than zero shot – when prompting your LLM to generate data, can you add an example? Multiple or more examples?
- Is there any additional information that you could provide that might help your model to create a good example?
- What quality assurance checks can you run on your generated examples? Can you improve the logic of these checks? Can you use the LLM again, this time for verification?
These new data generation capabilities are unbelievably potent!
A major problem right now are the licensing terms of the most capable models.
You cannot use data generated by OpenAI models to train models that might be used to compete with them.
Llama2 from Meta cannot be used by a company with more than 700k monthly users without direct permission from Meta. And more broadly, generations from Llama2 cannot be used to improve non-Llama models!
But even right now, there is a lot that can be done in a business context. And the capabilities of the open source models will only continue to grow.
The businesses and individuals who are able to navigate this new and exciting space will without a doubt thrive. So it might be worthwhile to get a head start!
For a consideration of a more modern training technique (the Low-Rank Adaptation, LoRA for short) I invite you to read the 2nd blog post in this series!
Also, the following video on generating new data by my friend Johno Whitaker is an extension of what I discuss above and well worth a watch!
Also, it turns out that the authors behind the DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing paper not only shared their repository for training/experiments with us, but they also include these terrific hyperparameter tables in the appendix!
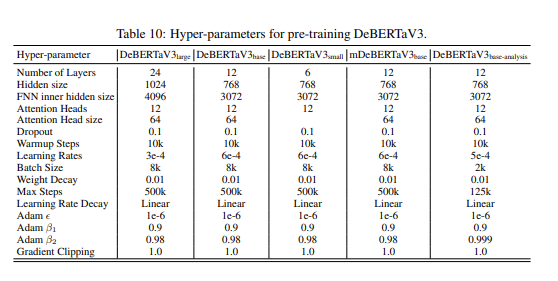

Turns out I wasn't that far away, but I would have loved to have come across these tables before I went looking at the repository!