How to train an Alpaca?


There used to be a time when fine-tuning LLMs on off-the-shelf hardware wasn't a thing.
Then the Llama weights got leaked, Stanford Alpaca was released, and the rest is history.
So how was Alpaca fine-tuned? And why might we care?
On one hand, Alpaca is where the Cambrian explosion of fine-tuned LLMs began.
Studying something that is bound to go down in the history of Machine Learning is very appealing in its own right.
But above all, the Alpaca code base is a great source of insight.
The code is legible, the data is there, and it all can be run on reasonable hardware within a reasonable amount of time.
It is a great starting point for anyone who wants to learn how to fine-tune LLMs.
So here are the experiments that I ran and what I learned along the way.
Fine-tuning Llama 2
I opted to fine-tune Llama 2 instead of Llama 1.
I ran the code from the Alpaca repository with the only change being swapping out the starting model.
Just like the authors, I trained on 4 A100s.
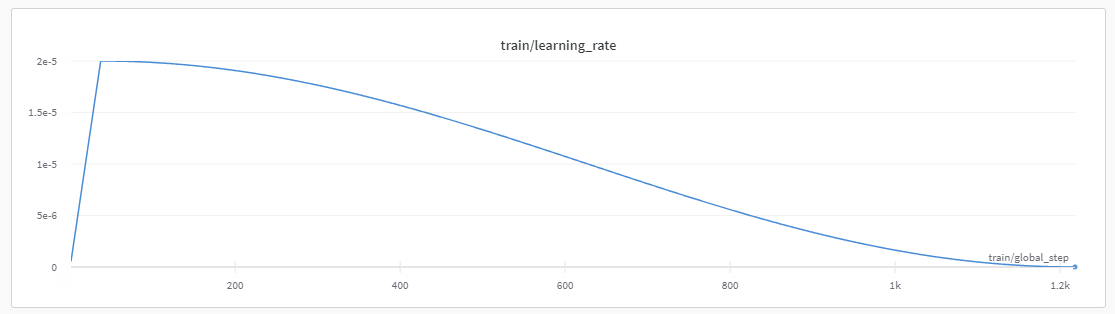
The training ran for 5 hrs and 30 minutes.
It was done over 3 epochs (with ~52 000 examples). The AdamW optimizer was used with a learning rate of 2e-5 and a cosine scheduler and a warmup of 0.03 with no weight decay.
The authors trained on 4 GPUs with 4 examples per GPU and 8 gradient accumulation steps. This gives us a batch size of 4x4x8 which is 128.
However, the crucial aspect of diving into a new area is being able to evaluate your results.
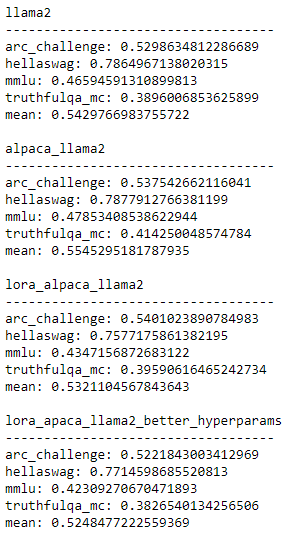
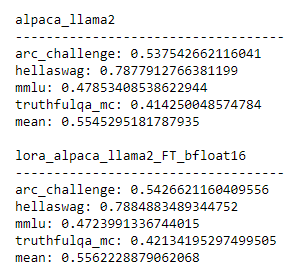
And so I ran the evaluation from the HuggingFace LLM leaderboard (using the Eleuther evaluation harness) and those are the results I got for the initial model and the fine-tuned one:
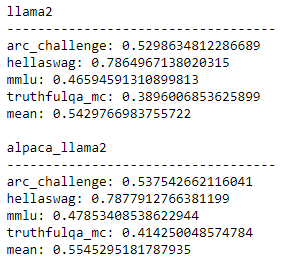
Phew, enough with the numbers.
You might think – if the authors trained on 4 GPUs with 4 examples per device and a gradient accumulation of 8, we should be able to train on a single GPU with a batch size of 4 and gradient accumulation of 32, right?
Unfortunately, that is not the case!
Alpaca was trained using Fully Sharded Data Parallel which does not only parallelize data across all GPUs, but also does so with model parameters, gradients, and optimizer states (with an optional offloading of the model's parameters to the CPU).
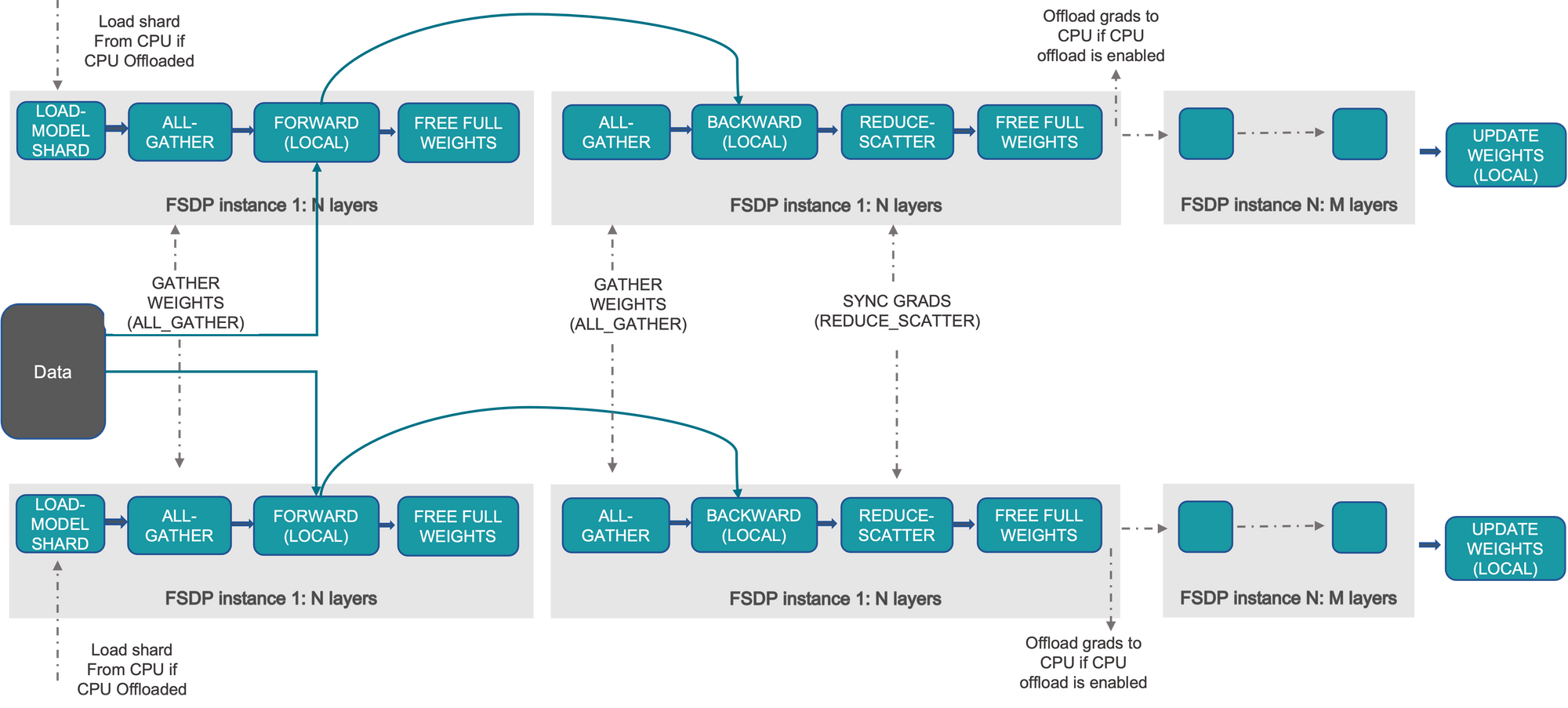
So the practical takeaway here is this – even using bfloat16, you will not be able to fully fine-tune a 7 billion parameter model on a single 80GB GPU!
Let's see if we can fine-tune the model to similar results with less hardware using LoRA.
But first, let's learn exactly how the model is trained.
What does the model actually see during training?
The beauty of Alpaca is how familiar it makes the arcane art of fine-tuning LLMs!
First of all, it uses the good old PyTorch Dataset.
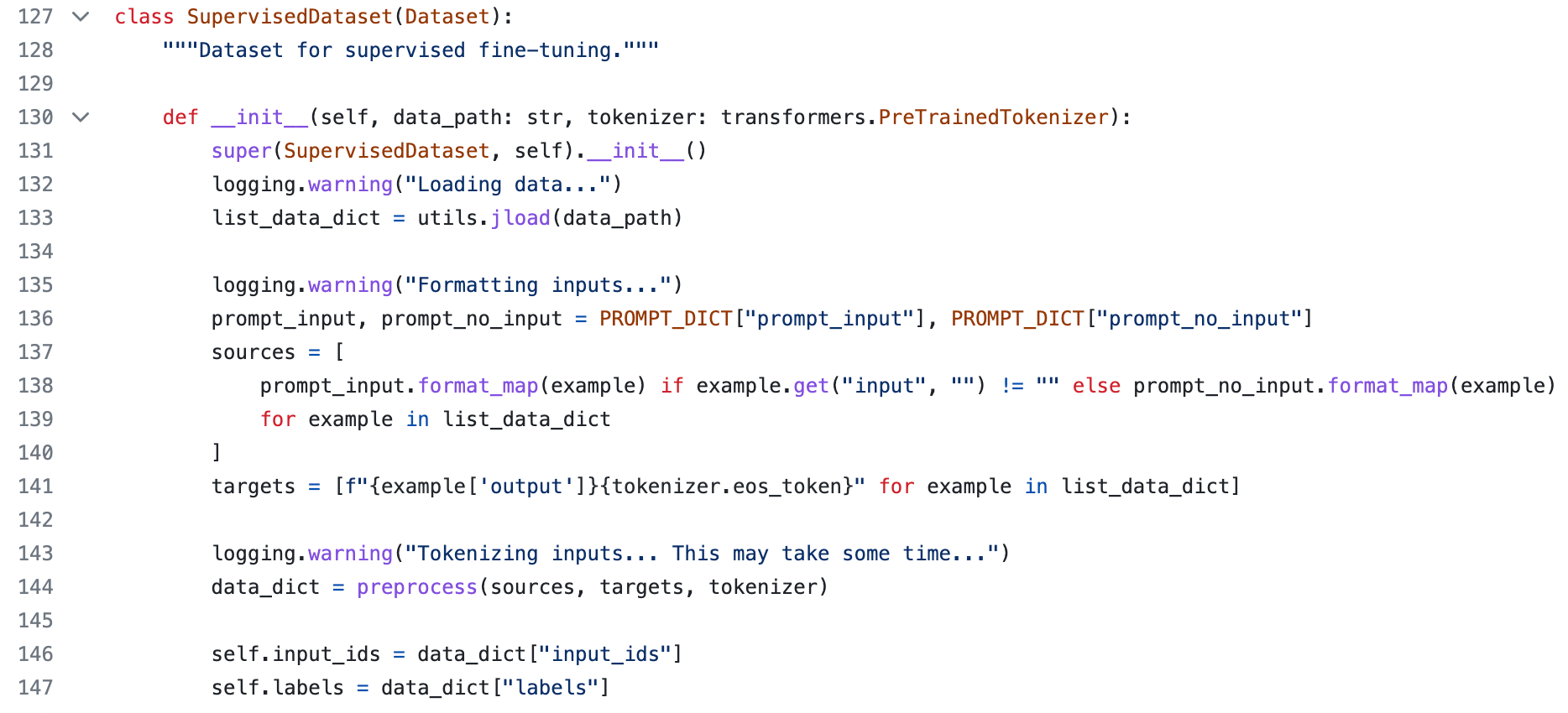
train.py is a joy to study!The base Llama model, being pre-trained on the next token prediction task, doesn't have a pad token.
Alpaca adds a pad token to the tokenizer and model embeddings and then does the absolutely most straightforward thing in the world!
We start with examples stored in json:
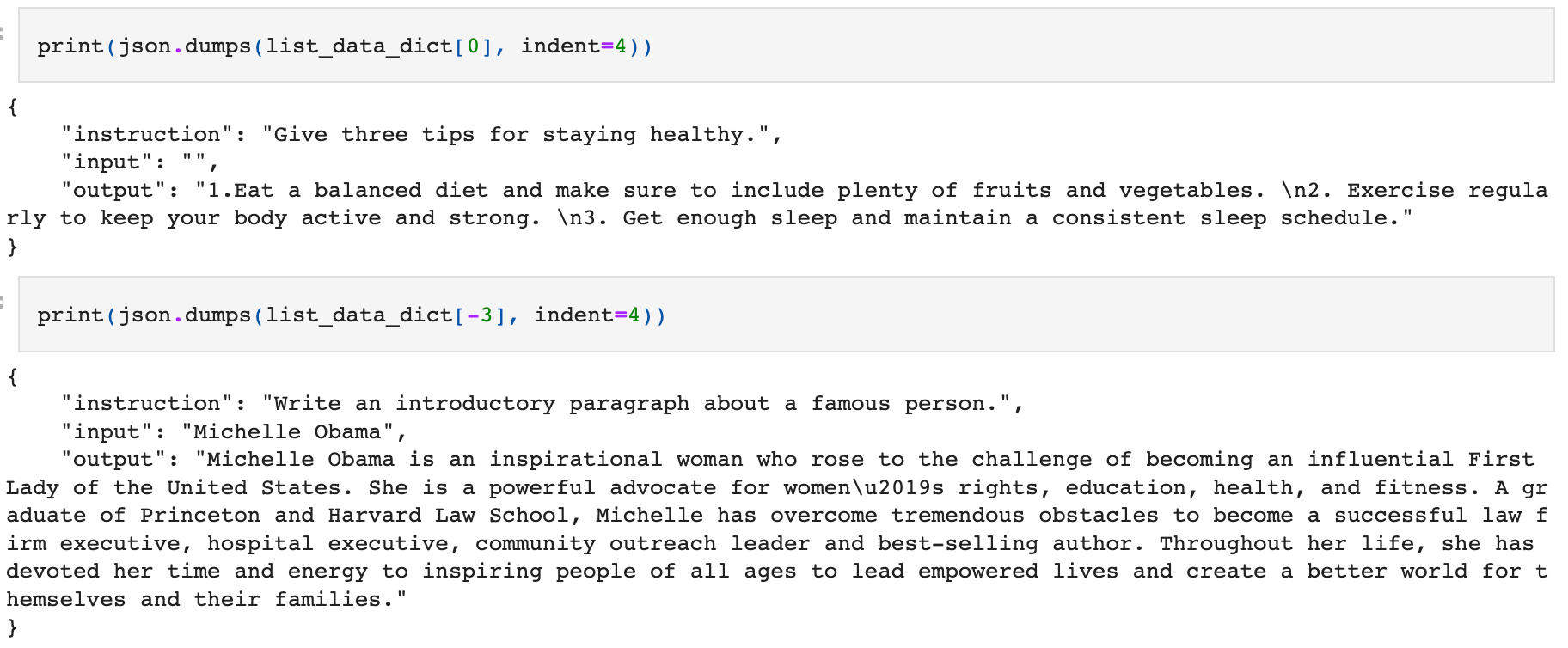
All examples have an instruction and an output. Some also have an input.
This information is turned into a prompt as follows:
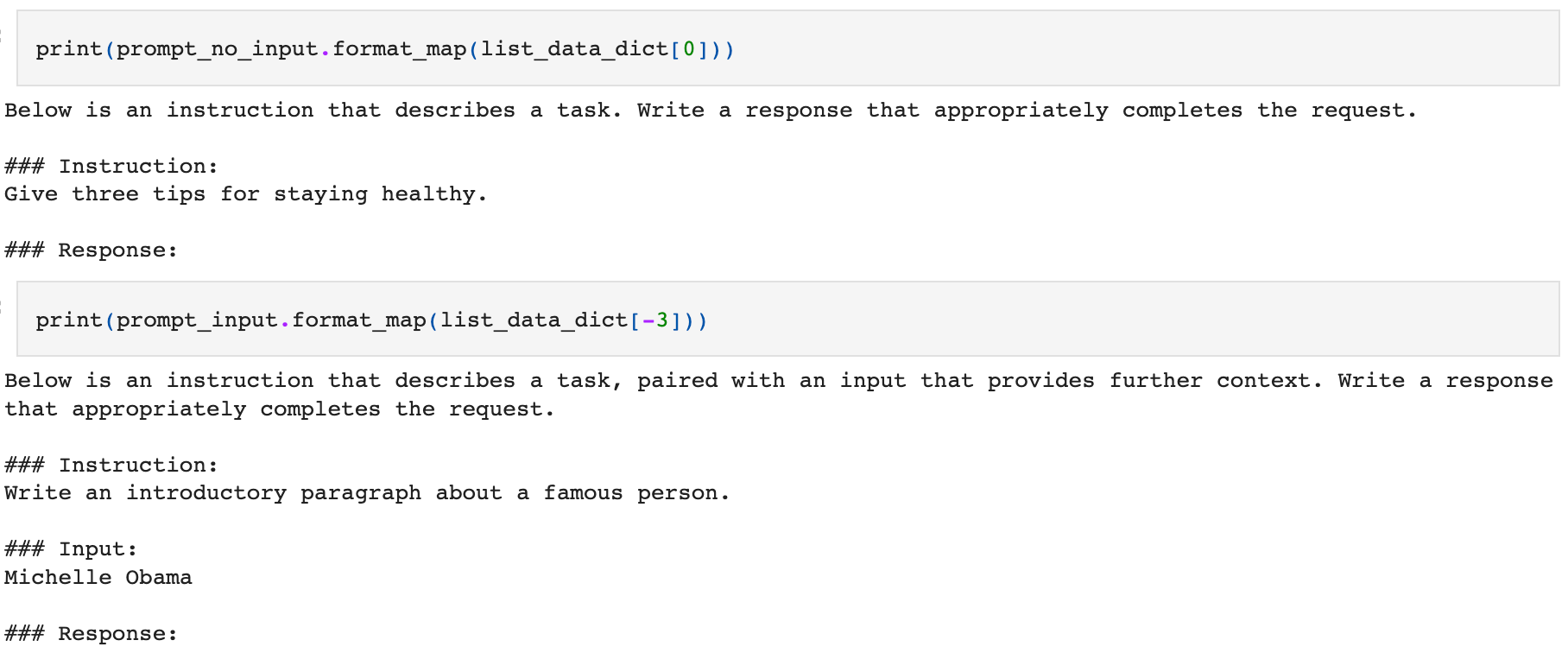
We append the output to the prompt, manually add the EOT (end of text) token, and tokenize the whole thing.
The key insight is this – we train on the next-token-prediction task and calculate the loss only with regard to the desired output!
We do not backpropagate the loss through the tokens generated for the instruction and input portions of our examples.
Can we fine-tune the model on a single GPU?
I wrote a training loop with LoRA (we dived into LoRA in an earlier blog post) and trained on a single A100.
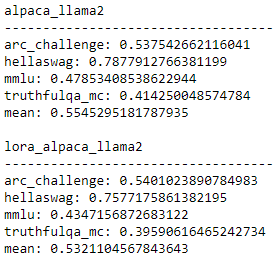
The model improves on some tasks but worsens on others.
LoRA is completely new territory for me so I decided to use a proven recipe.
The effective batch size is now 8 and I train with a much higher learning rate of 2-e4. You can find the code here.
But the biggest change is in the LoRA configuration. We are now attaching LoRA adapters to many more layers:
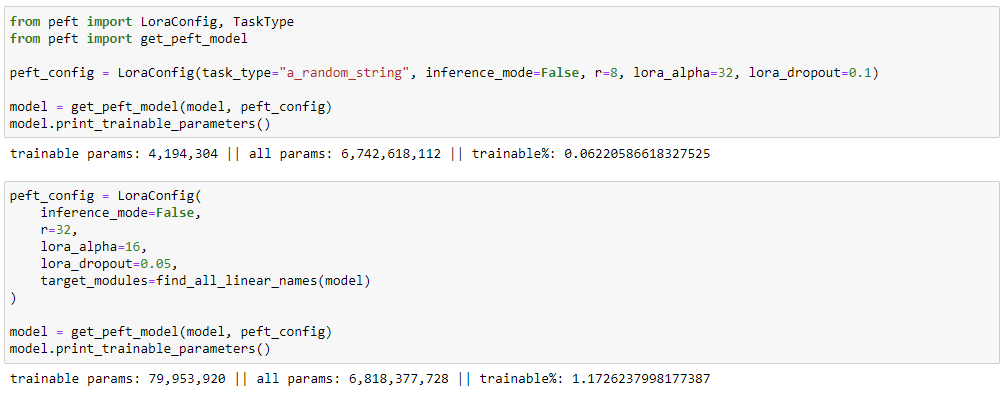
And the model does train. We are modifying the behavior of the model and the train loss reaches a lower value than when we trained with a more limited LoRA config.
Unfortunately, the model doesn't improve.
Summary
Fine-tuning LLMs currently feels like the Wild West.
There are many exciting developments.

But overall, we all are just trying to make sense of what is going on.
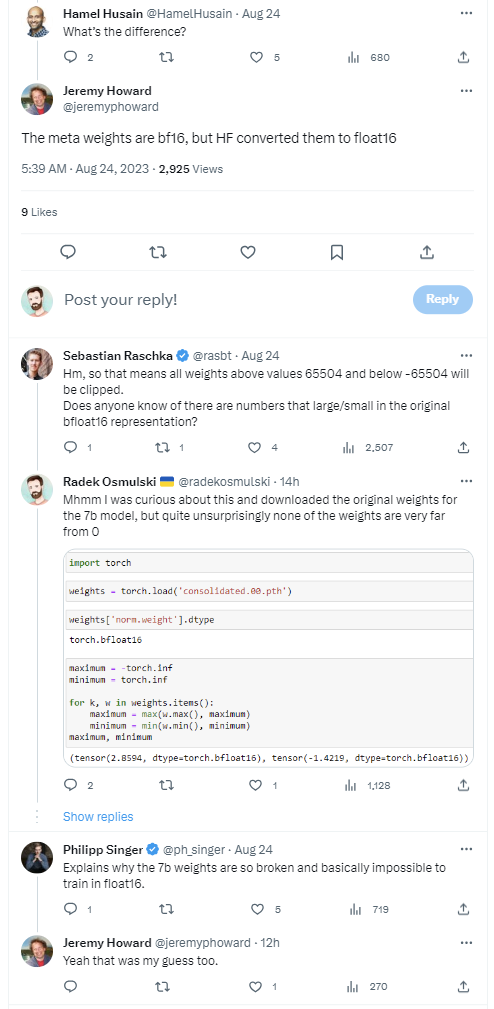
And when someone stumbles into something that works we all jump on (if we are lucky to be in the vicinity when the discovery is announced) and hold onto the precious insight.
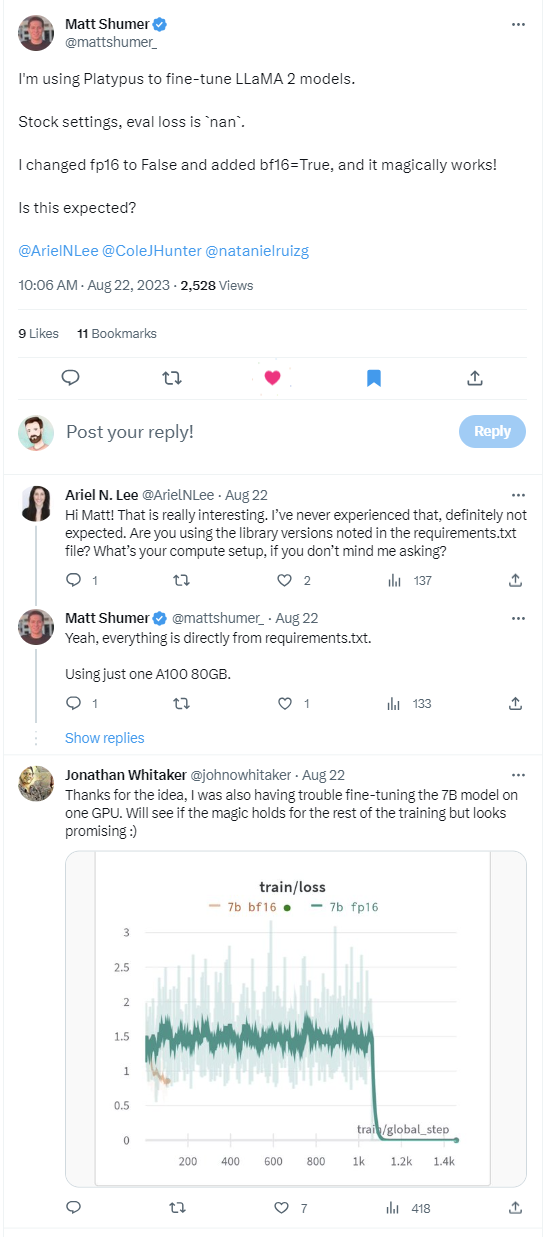
bfloat16?Additionally, cutting-edge libraries are bugged into oblivion, and if you make just one change from the published example you are likely to stumble into a bug.
Among it all, Stanford Alpaca stands out as a beacon of hope. Yes, the data it was trained on might have been cleaner. And the recipe is very basic.
Maybe, in retrospect, the use of 4 A100s wasn't efficient. Or maybe full fine-tuning should always be the way to go if you have the hardware for it?
Who knows.
The beauty of Alpaca lies in its simplicity and the fact that it demonstrably works.
It takes the training of LLMs from the hands of companies with heaps of hardware and puts it in the hands of an average Joe.
Inspired by it, I ride into the setting sun hopeful for the training runs I will kick off tomorrow.

PS. No rest for this cowboy! As it turns out, you can (probably) fine-tune a 7b model on a single 80GB GPU in half precision.
And half-precision (or its most recent incarnation, bfloat16) feels like standard training to me.
I incorrectly assumed that accelerate will magically cast everything for me to bfloat16.
But that is not the case!

You have to load the model in bfloat16 (or cast it to the desired dtype before handing it over to accelerate) and then everything works.

Interestingly, Stanford Alpaca was also trained in bfloat16!
Now, GPU memory consumption does fluctuate slightly with (I assume) the length of an example.
But I just started a new training run, on a single 80GB A100, and assuming it doesn't crash due to OOM, we will have Alpaca fine-tuning in one notebook on a single 80GB GPU!
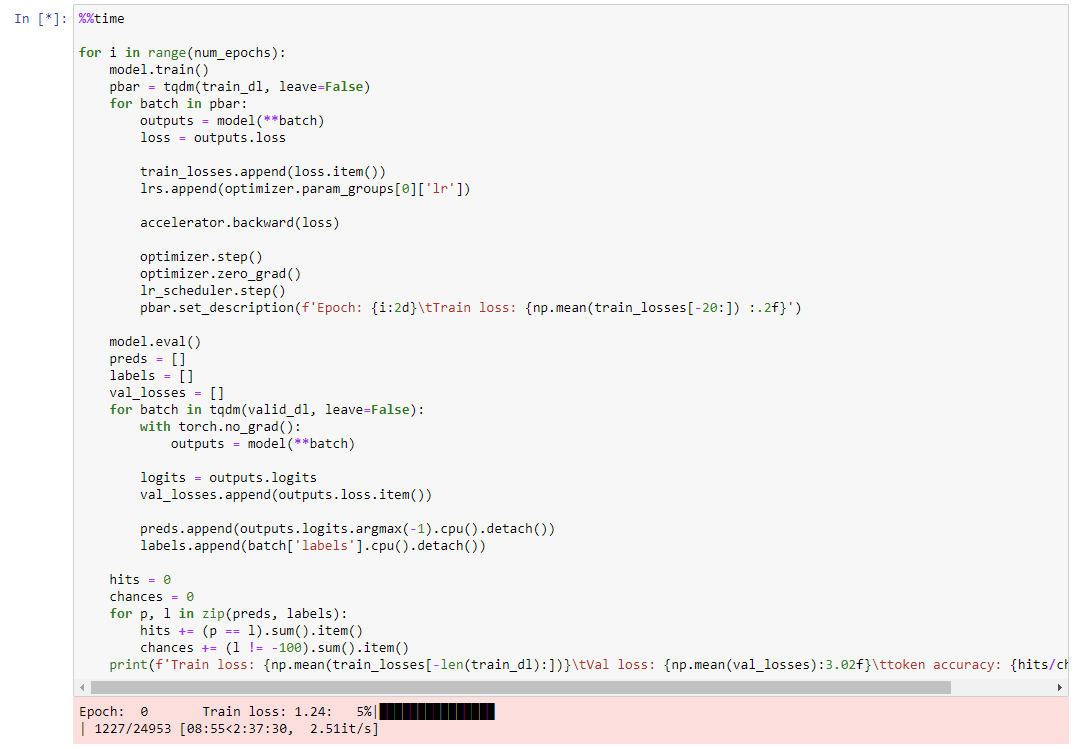
We are very close to the danger zone, though!

Now, you may ask, what good would being able to reproduce Alpaca on a single 80GB be?
Training on a single GPU is the most efficient in terms of GPU usage, the hassle you need to go to set things up, and the money spent!
But more importantly, if we can comfortably get to training with bfloat16 on a single GPU with 80GB, that means that with quantization and/or layer freezing, we can go even lower 🤠
Will update this blog post with the results of the run, when it completes or fails.
UPDATE: The training ran without issues! And we achieve a comparable result to the original fine-tuning done using the Alpaca repository.
Here is the code I used for this run.