Introduction to data augmentation and pseudo-labeling
A closer look at two techniques that can help you make the most of your training data.


This blog post was originally published on Medium on 10/10/2017.
In order to get a better feel for the techniques, we will apply them to beat the state of the art from 2013 on distinguishing cats and dogs in images. The plot twist is that we will only use 5% of the original training data.
We will compete against an accuracy of 82.37% achieved using 13 000 training images. Our train set will consist of 650 images selected at random.
Models will be constructed from scratch and we will not use transfer learning nor pretraining.
You can find the code I wrote working on this in my repository on Github.
First model
The first model has to be very simple — 650 images is a really small amount of data.
I go for the CNN architecture which limits the number of weights by exploiting the fact that similar shapes can be found in nearly any position in the image.
I also skip the fully-connected classifier and instead decide on a fully convolutional network. The hopes are that this will give our model a better chance to generalize.
Above all, I experiment a lot. The final architecture contains 28,952 trainable parameters across 6 convolutional blocks. With a small amount of l2 regularization, the model achieves 74.38% accuracy on the 23,750 images in the test set.
Time to roll out Big Idea #1.
Data augmentation
How can we make a model perform better? Training it on more examples while ensuring it has the capacity to learn is generally the right approach.
But in practice, more training data is often not easy to come by. Obtaining or annotating additional examples can be tedious or expensive.
Another thing we could do is use what we know about images to emulate having more of them.
Would a picture look much different if it was taken from a smaller distance? Not really. Can we emulate this? Absolutely! Blow the picture up and crop the center.
What about making it seem as if a picture was taken with a camera positioned slightly to the right? No problem at all. Shift the image a tiny bit to the left.
This sounds easy enough and can be very powerful. The only minor detail to add here is that we will not be transforming the images ourselves — we will tell an algorithm what transformations it is allowed to do and it will take some random combination of them.
Unfortunately, to learn from augmented data I need to construct a much bigger model. It ends up containing many more feature maps bumping the trainable parameter count to 1 003 682.
This seems a bit off. Maybe the architecture I have chosen has not been that great to start with. At this point, however, I chose to stick with it and continue the experiment.
With data augmentation, the model improves on earlier results by 35% and achieves an accuracy of 83.43% on the test set.
Time for Big Idea #2.
Pseudo-labeling
Could we somehow use the model itself to again emulate having more data?
Theoretically, we could take all the unlabeled data that we have, including our validation set, run the model on it and add the images where our model feels most confident about its predictions to our train set.
Aren’t we risking reinforcing the mistakes that our model is already making? By all means, this will happen to some degree.
But if things go as intended the benefits of doing this will outweigh the aforementioned effect.
What we are hoping for is that by being presented with more data our model will learn something about the underlying structure shared by all the images that potentially it could see. And that this will be useful to it for making predictions.
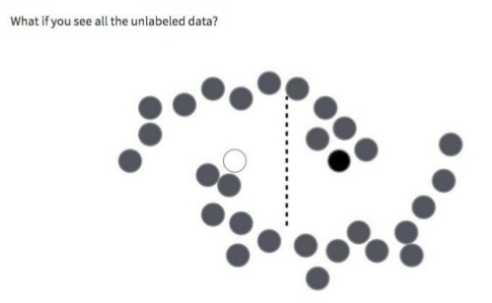
To learn from pseudo-labeled images I construct a model that is 1.5 times bigger than the previous one. We are now at 1 566 922 trainable parameters.
I run the old model on the 24,350 unlabeled examples. I pick 1000 images where it feels most confident it is right. I train our bigger model on a mix of pseudo-labeled and original train set images using proportions of roughly 1 to 4.
With no experimentation with the model architecture and no tweaking of the mixing ratio, the new model achieves an accuracy of 85.15% on the test set and quite confidently beats the SOTA from 2013.
Summary
I wrote this article before completing the Practical Deep Learning for Coders course by fast.ai. I now would approach this challenge differently. I would go for the Densenet architecture which seems to do extraordinarily well with small amounts of data. I would also not resize the images but instead would blow them up and crop them to the shorter side. This loses some information but it keeps the aspect ratios intact which generally works better.