How to Do ML on a Remote Machine with Ease


The article below consists of two parts. In the first part, I share my workflow for working on remote machines. I am using Lambda Labs, but the steps can be easily adapted to working on a remote machine of any kind.
In the second part, I share more general thoughts on how to source hardware for your projects and reflect on how this has changed over the last couple of years.
My Remote Machine Workflow
It all starts with a notion page simply named Scratchpad.
Here's where I will collect all the commands I need to ctrl-c ctrl-v into a freshly booted-up machine as I continue working on my project.
I start with just a single command:
This will clone a private repo with all the non-project-specific, tedious-to-perform-by-hand configuration steps.
This is the script from the repo that I run:
git config --global user.email <YOUR_EMAIL_ADDRESS>
git config --global user.name "<YOUR_NAME>"
bash install_nodejs_and_cc.sh
pip install -U ipython ipykernel nvitop git+https://github.com/AnswerDotAI/execnb.git
########## .bashrc modifications ##########
# Create a temporary file with lines to add to .bashrc
cat > /tmp/bashrc_additions << 'EOF'
alias gu='git commit -am update && git push'
alias gs='git status'
alias gp='git push'
export KAGGLE_USERNAME=<YOUR_KAGGLE_USERNAME>
export KAGGLE_KEY=<YOUR_KAGGLE_API_KEY>
export WANDB_API_KEY=<YOUR_WANDB_API_KEY>
EOF
# Add only lines that don't exist
while IFS= read -r line; do
grep -Fxq "$line" ~/.bashrc || echo "$line" >> ~/.bashrc
done < /tmp/bashrc_additions
# Clean up
rm /tmp/bashrc_additions
#############################################The reason I can clone this private repository from GitHub straight after sshing into the remote machine, without any other configuration steps, is agent forwarding.
I can activate agent forwarding by modifying the ssh command, via an entry in ~/.ssh/config, or if you follow the batteries-included recipe below, all this will be done for you.
Let's spin up our machine now and get started working on our project.
Booting Up and Connecting to the Remote Instance
I hate web UIs with great passion. For a better experience in managing your cloud resources, you nearly always want to use command-line interfaces.
To spin up our machine, we will use the unofficial Lambda Labs api client, created using Claude Code by yours truly.
After following the api client installation steps, all you have to do is execute lambda-labs from your command line, and you will be brought to the following view:

We select Launch a new instance and are presented with the following table:
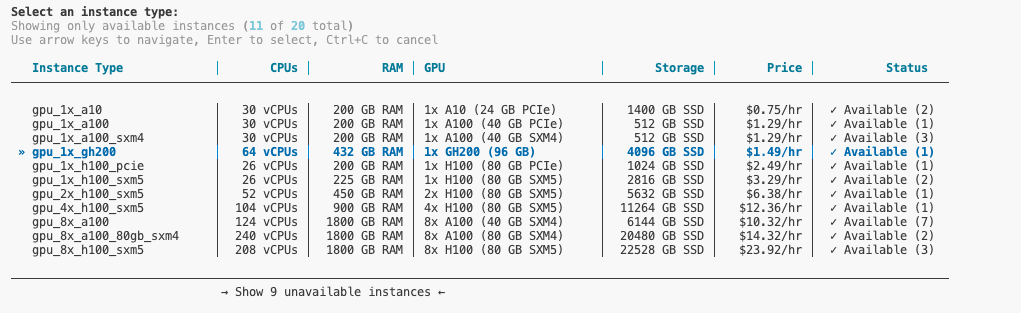
Clearly, the GH200 is the answer to most questions in our lives, so we select that instance type. Or we pick any other instance type that suits our needs.
If the instance type we would like to spin up is unavailable, we can go to Show unavailable instances and opt to queue for the instance and grab it as soon as it becomes available.
The instance launches, and initially, it will be in a booting state:

This process can take several minutes, so it is a good moment to work on something else.
In the meantime, we can also automatically add our new machine to our ssh config by selecting Manage SSH config and clicking through the options:

You can hit [Refresh] every now and then to see if the instance has booted up yet.

As we are up and running now, it is time to ssh into our instance.
I used to be a die-hard vim user, but now I nearly exclusively use Visual Studio Code as my daily driver.
I press cmd-shift-p to activate the tool palette and select Remote SSH: Connect to Host...
I start typing in lambda and our newly booted machine appears in the list of machines to connect to:
I press enter, and I am taken to my remote machine.
I open a terminal (cmd-shift-`) and move it to the left-hand side (the trick is to right-click on the invisible bar on top of the open terminal and select Panel position > Left). I copy over the setup commands from Scratchpad and press enter to run them (currently just a single line, but this is likely to evolve as I continue to work on the project).
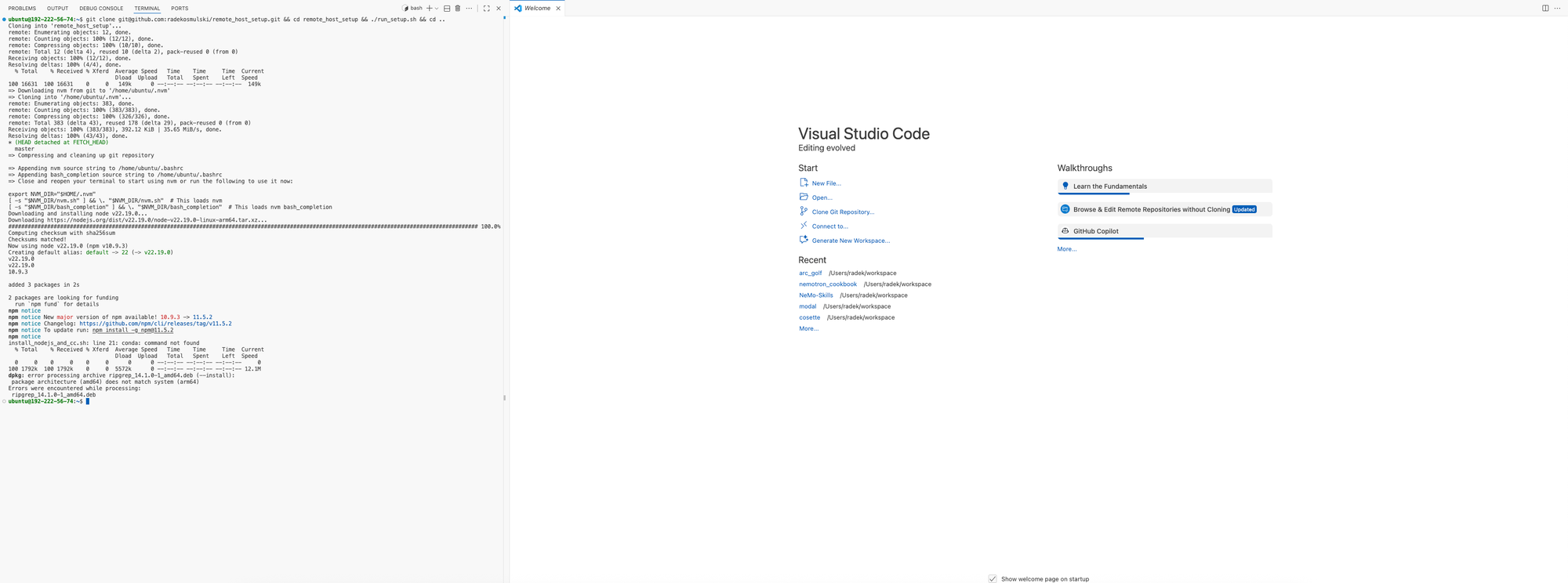
Immediately, I see I need to enter another line to my Notion page:
git clone git@github.com:radekosmulski/remote_host_setup.git && cd remote_host_setup && ./run_setup.sh && cd ..
source ~/.bashrc && claudeNow I have Claude Code running in the first terminal tab, and I open a new tab to do additional work:
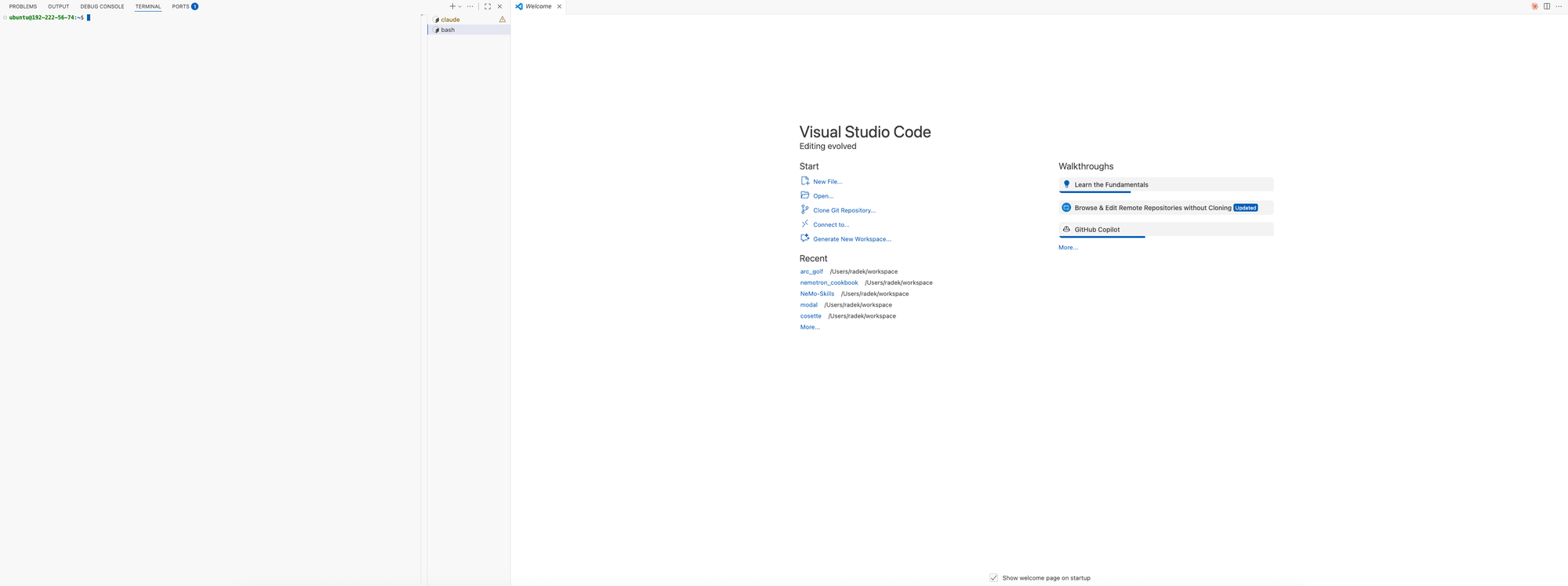
Look at all the real estate on my screen that I can use! Plus, I have configured keyboard shortcuts that allow me to move around without lifting my hands off my keyboard.
This is what my keybindings.json looks like (with some convenient bindings for managing Jupyter Notebook kernels).
At this point, I have a machine ready for development work that:
- has the custom hardware I need for the current phase of my project
- has all the major conveniences of my local machine, through the magic of Visual Studio Code, and executing the setup script
The general lay of the land looks as follows:
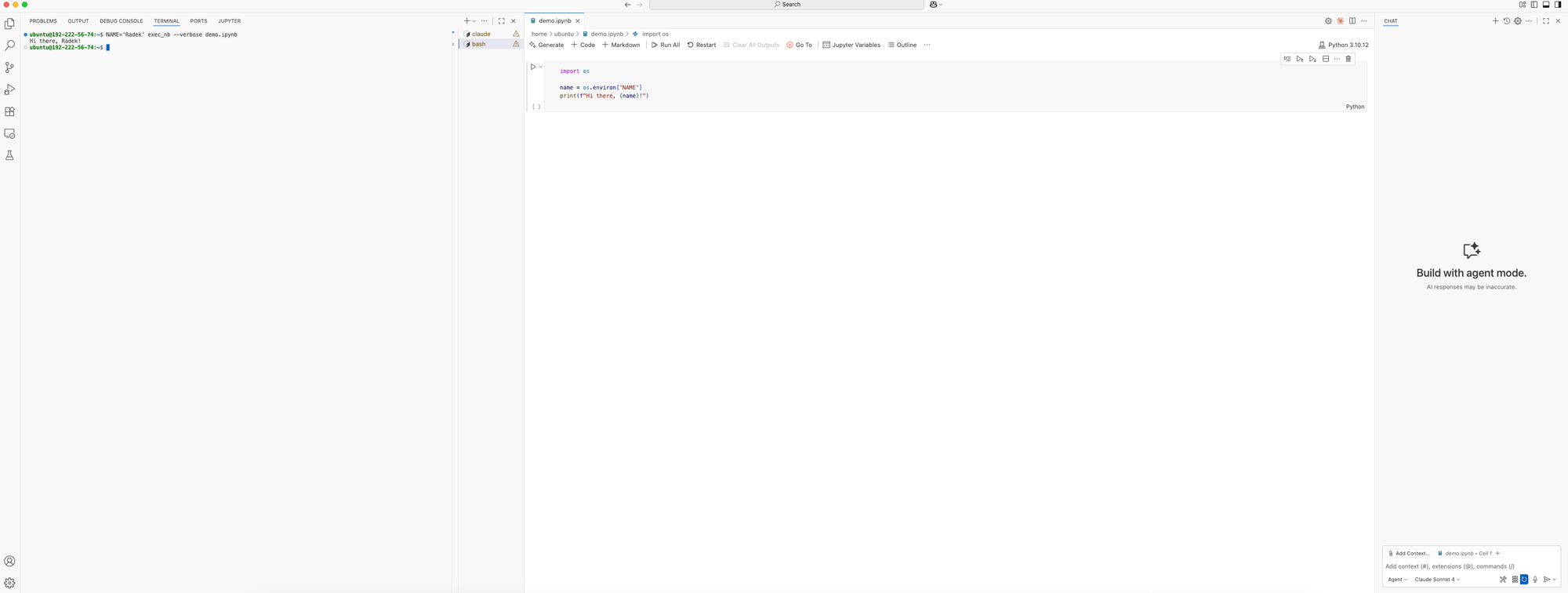
- terminals in tabs on the left
- Jupyter Notebook with LLM completion in the middle
- LLM chat with agentic capabilities on the right (I use this feature quite rarely – I get more mileage out of either Claude Code or the Claude web UI)
Other key points:
- I can develop in Jupyter Notebook without having to forward any ports, can explicitly start a Jupyter Notebook server, etc
- I run the code in my Jupyter Notebooks using
nbexecfrom answer.ai.
This is what my notebook looks like (to run the notebook itself, you might need to install the Jupyter Notebook extension and select global Python as your kernel of choice):
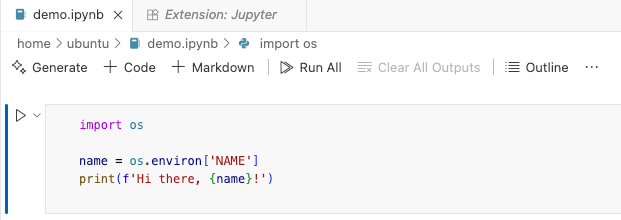
And this is how it behaves when run:
ubuntu@192-222-56-74:~$ NAME='Radek' exec_nb --verbose demo.ipynb
Hi there, Radek!- I pass arguments to my notebooks using environment variables
- I start long-running jobs in tmux:

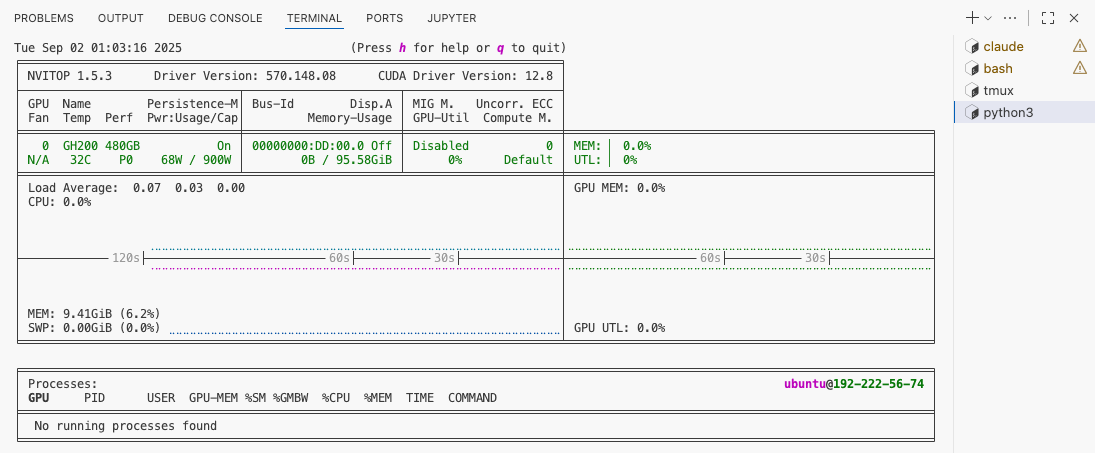
- All the functionality I might need is just a keybinding away! (
ctrl+shift+`, typenvitop, and pressenterfor this particular one)
Adapting This Workflow
This setup is highly adaptable to your project's unique needs. I developed it with a single goal: to explore and ship greenfield machine learning projects as fast as possible.
That also entails designing the experience in a way as to expend the least amount of mental energy on maintaining the scaffolding of your project.
Along the way, I considered and made deliberate choices about:
- Benefits and tradeoffs of certain approaches (for instance, the dangers of passing arguments via environment variables versus the code streamlining that it offers)
- How to leverage LLMs at every stage of development
I've consciously optimized this workflow for speed and iteration. Your priorities or environment might differ, and that is okay.
I'll be writing more about using this setup to solve real ML problems, but I wanted to share these tools now in case even one or two ideas prove helpful.
Thoughts on sourcing compute for your projects
We live in a weird era for personal computer hardware.
On one hand, having your own machine that you have full control over is still the most comfortable way to work and the easiest and quickest way for newcomers to get started.
On the other hand, my Quadro 8000, a 48GB beast of a card, is now obsolete, and I don't have good options for an upgrade.
Despite the pace of innovation, the current generation of hardware will still easily serve you for a couple of years. Plus, on a pure dollar value, I bet that a card like the RTX 5090 is a good investment. I got 4 years of usage out of my 1080 Ti and sold it for the same amount I paid for it.
But back then, I could throw my 1080Ti against anything I might want to work on, and it would do a decent job at it. A computer vision problem, an NLP problem, accelerating a data processing pipeline, some other custom algorithm, etc.
Today, I might want to use a frontier model for some aspect of work. I might then want to run inference against a 49B model, or a 9B model, for this task or another.
And even if I wanted to do some good old model training, I don't want to be limited to 32GB of RAM!
It might just be that in the not-too-distant past, a personal rig you could ssh into was the best center of operations for honing your skills and working on interesting projects.
But today, this role is increasingly played by a laptop with a decent amount of RAM that you can use to tap into remote resources such as machines for training your models (Lambda Labs) or inference providers (Modal, OpenRouter, etc).
Add to that Visual Studio Code and LLM code completion, sprinkle a few coding agents here and there, and you are set.
But there might also be another thing at play here. My life circumstances and my skillset have also changed over the last couple of years.
I am now much more likely to use the right tool for the job, even if it might not be the cheapest solution.
Also, over the last couple of years, I have spun up multiple jobs each day, commanding various node configurations on computer clusters to do my bidding. This is my bread and butter now.
This means that many of the drawbacks of running in a distributed setting (and there are many) are no longer a deal breaker for me. I barely notice them, and if I do, they are just minor nuisances to work around.
So if I can get a GH200 with 96GB of GPU RAM, 432GB CPU RAM, 4096GB fast, locally connected storage, and 64 vCPUs from Lambda Labs for $1.49/hr (which is up to 20x faster in actual workloads than my Quadro 8000 system), it is hard to say no.
Additionally, between the code tools and remote resources that I use, I now spend hundreds of dollars each month out of my own pocket.
And the situation gets even murkier when I see friends creating courses that offer compelling deals—like 2.5x compute credits per dollar when you sign up early, plus the unbelievable educational value of the course itself.
Zach (@TheZachMueller) cultivated so much FOMO that companies offering compute far in excess of what his course costs 🤯
— Hamel Husain (@HamelHusain) September 1, 2025
Also, its basically a distributed model training conference based on the stacked guest speakers https://t.co/sggDfjBEV4 pic.twitter.com/7loBhxH66o
To summarize, finding the right compute resources for personal projects—whether for Kaggle competitions or learning new technologies—remains an open question for me.
I'll continue exploring all available options, including building a better local setup. However, given current trends, remote computing will likely become increasingly important over the coming months and years.
This blog post aims to address that reality. The techniques I've shared here can hopefully streamline your remote workflow, letting you spend less time fighting with tools and more time on the actual work that matters.