How to do machine learning efficiently The only way to maintain your sanity in the long run is to be paranoid in the short run.
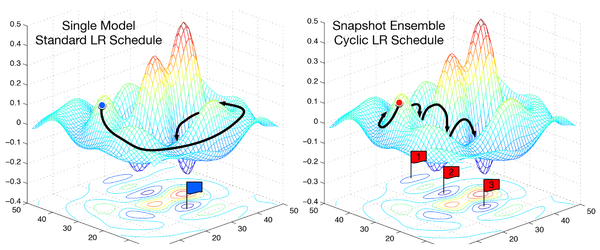
Do smoother areas of the error surface lead to better generalization? An experiment inspired by the first lecture of the fast.ai MOOC
Introduction to data augmentation and pseudo-labeling A closer look at two techniques that can help you make the most of your training data.
Can we beat the state of the art from 2013 with only 0.046% of training examples? If we take the CNN layers of a pretrained model, how much data would we need to recover some of the mappings from features to classes? As it turns out, very little!
howto Automated AWS spot instance provisioning with persisting of data After following this guide, you will be able to spin up an AWS EC2 spot instance by executing a single command from your terminal. The instance will have a volume attached that will be persisted across shutdowns.